# 前言
前几个星期我通过看网课来学习python,但是由于效率太低,于是这两个星期在学姐的帮助下初步接触了数据分析的相关知识,第一个了解到的就是pandas,故利用本周的博客来记录我初步学习利用pandas进行简单数据分析的过程。首先是对pandas包进行了安装,然后上网查询了pandas的一些基础命令,接着对网上关于利用pandas进行数据分析的简单项目进行学习。
除此之外,还将总结一些本周学习到的关于python需要注意的tips。
# 数据分析
数据分析的流程概括起来为:数据的读写-->数据的处理和计算-->数据的分析建模-->数据的可视化
# pandas
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。;;
# 利用pandas做简单的数据分析
# 了解数据
主题:探索Chipotle快餐数据
import pandas as pd # 导入必要的库
path1 = "../input/pandas_exercise/exercise_data/chipotle.tsv" # 导入数据集
chipo = pd.read_csv(path1, sep = '\t') #将数据存入一个名为chipo的数据框内
chipo.head(10) # 查看前10行的内容
2
3
4
运行结果:
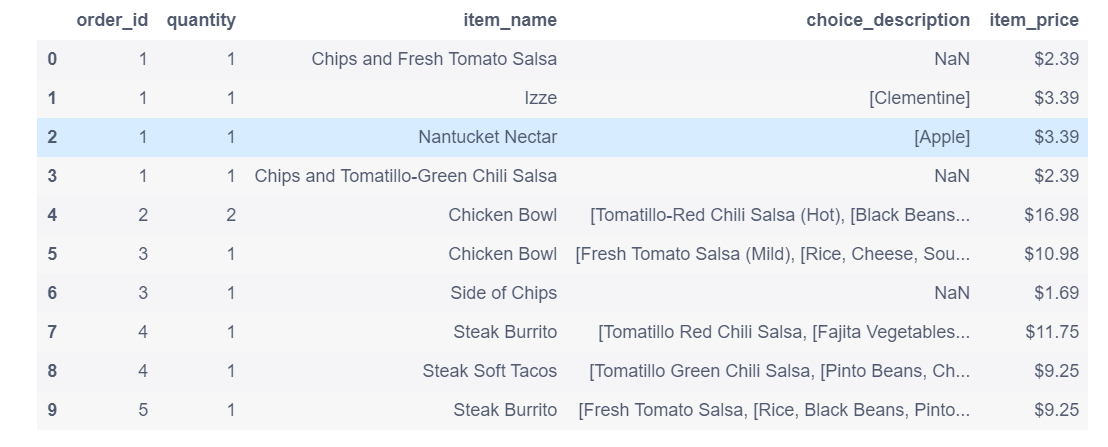
# 被下单数最多的item是什么
c = chipo[['item_name','quantity']].groupby(['item_name'],as_index=False).agg({'quantity':sum})
c.sort_values(['quantity'],ascending=False,inplace=True)
c.head()
2
3
4
5
out:
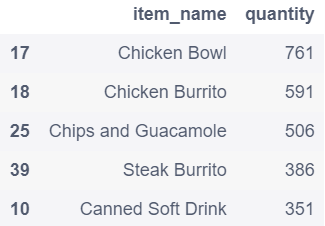
总结:利用pandas做数据分析,首先需要引入pandas库,然后需要导入数据集(为我们收集到的数据资料),我们可以通过简单的命令来得到数据的县官信息。
# 数据的过滤与排序
主题:探索2012欧洲杯数据
import pandas as pd
path2 = "../input/pandas_exercise/exercise_data/Euro2012_stats.csv"
euro12 = pd.read_csv(path2)
euro12
# 显示数据框具体信息
euro12.shape[0]
# 求数据共有多少列
euro12.info()
# 筛选数据并创建新的数据框
discipline = euro12['Team','Yellow Cards','Red cards']
discipline
2
3
4
5
6
7
8
9
10
11
out:
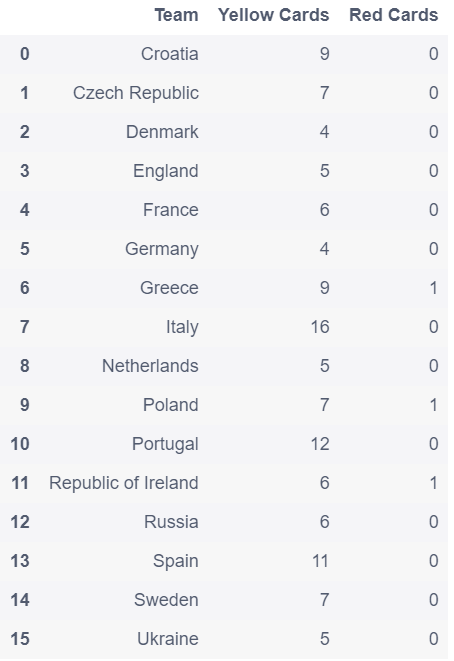
# 对数据框按顺序排序
discipline.sort_values(['Red Cards','Yellow Cards'], ascending = False)
2
out:
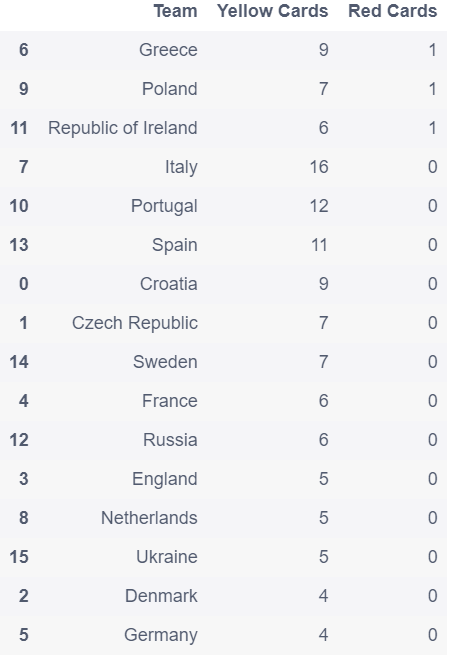
# 计算平均值
round(discipline['Yellow Cards'].mean())
# 筛选符合标准的数据(goal是大于6)
euro12[euro12.Goals > 6]
# 选取以字母G开头的球队数据
euro12euro[Team.str.startswith('G')]
# 选取前7列
euro12.iloc[: , 0:7]
2
3
4
5
6
7
8
out:
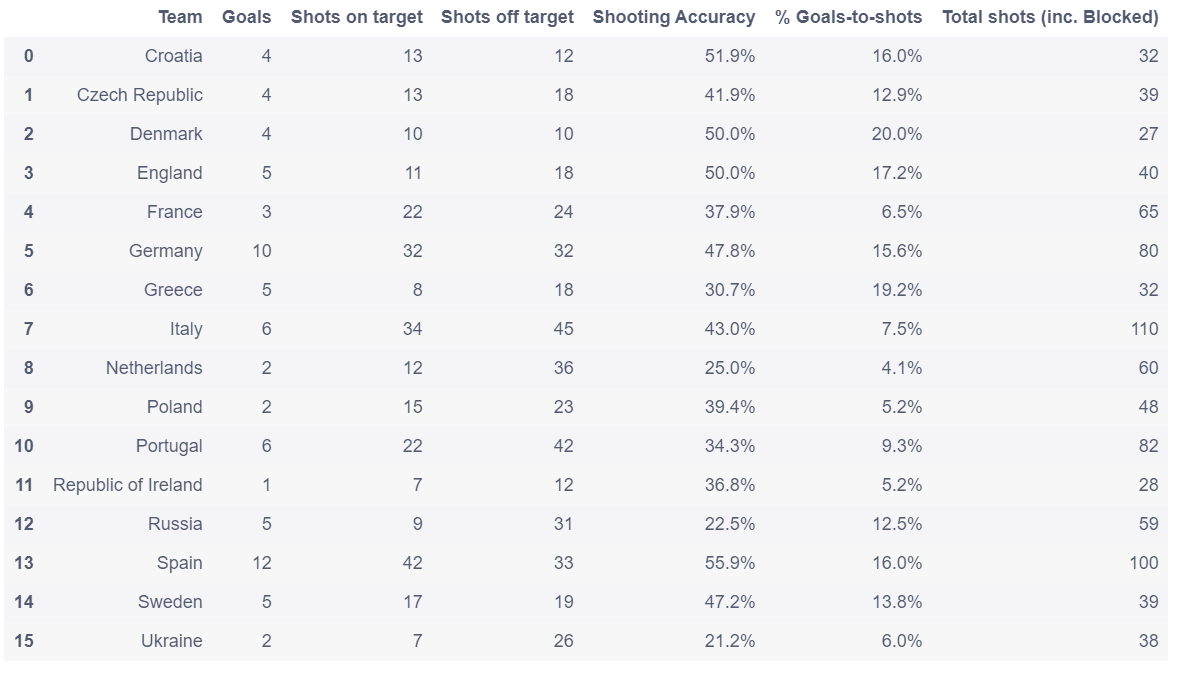
# 选取除了最后3列之外的全部列
euro12.iloc[: , :-3]
# 找到特定数据
euro12.loc[euro.Team.isin(['Enland','Italy','Russia']),['Team','Shooting Accuracy']]
2
3
4
out:
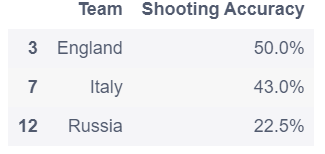
总结:python中要想实现对数据的调用,需要一些函数,他们通常是有关数据的英文单词的缩写,重要的是牢记他们的用法与格式
# Apply函数
主题:探索1960 - 2014 美国犯罪数据
import numpy as np
import pandas as pd
path4 = '../input/pandas_exercise/exercise_data/US_Crime_Rates_1960_2014.csv'
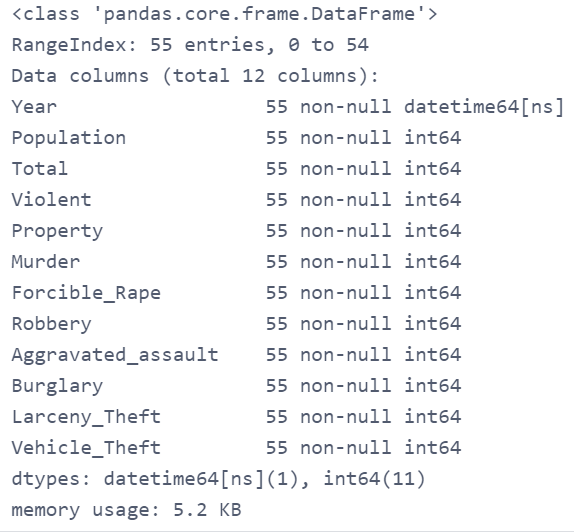
crime = pd.read_csv(path4)
crime.head()
# 将Year的数据类型转换为 datetime64
crime.Year = pd.to_datetime(crime.Year,format='%Y')
2
3
4
5
6
7
out:
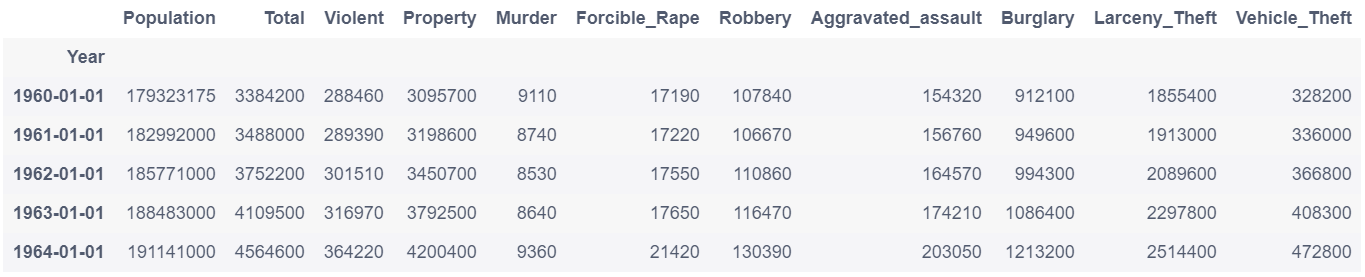
# 将列Year设置为数据框的索引
crime = crime.set_index('Year',drop = True)
2
out:
# 删除列
del crime['Total']
# 求最大值
crime.idxmax(0)
2
3
4
out:
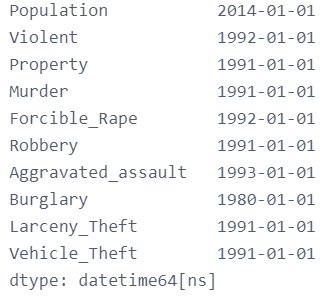
总结:pandas中set_index添加索引 DataFrame通过set_index方法,可以设置单索引和复合索引。 DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False) append添加新索引,drop为False,inplace为True时,索引将会还原为列
# 可视化
主题:探索泰坦尼克灾难数据
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
%matplotlib inline
path7 = '../input/pandas_exercise/exercise_data/train.csv'
titanic = pd.read_csv(path7)
titanic.head()
titanic = titanic.set_index('PassengerId').head()
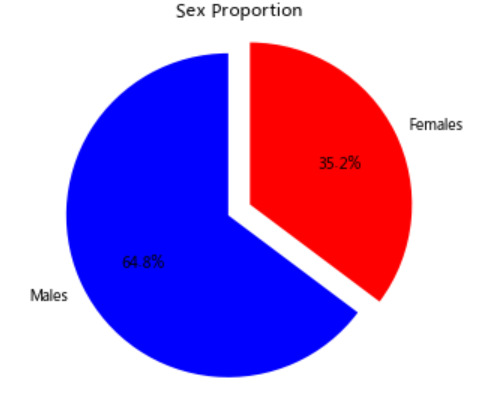
# 绘制一个展示男女比例图的扇形图
males = (titanic ['Sex'] == 'male').sum()
females = (titanic ['Sex'] == 'female').sum()
proportions = [Males, Females]
plt.pie(
proportions,
lables = ['Males', 'Females'],
shadow = False,
colors = ['blue', 'red'],
explode = (o.15, 0)
startangle = 90,
autopct = '%1.1%%f',
)
plt.axis = 'equal'
plt.title("Sex Proportion")
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
out:
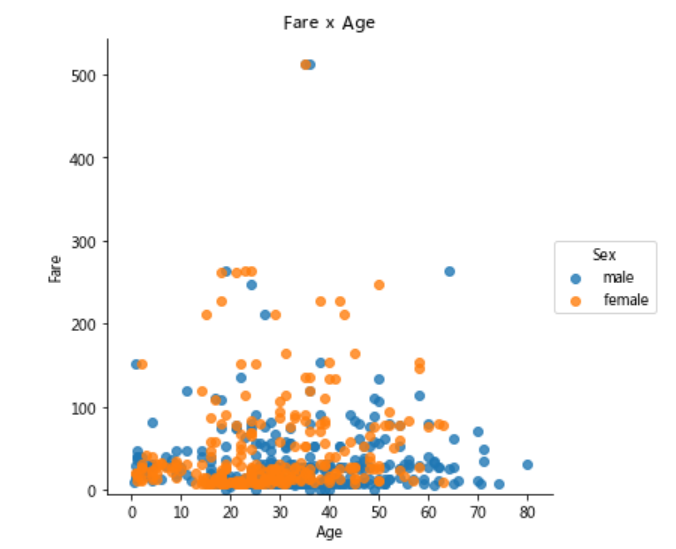
# 绘制一个展示船票Fare, 与乘客年龄和性别的散点图
lm = sns.lmplot(x = 'Age', y = 'Fare', data = titanic, hue = 'Sex', fit_reg=False)
lm.set(title = 'Fare x Age')
axes = lm.axes
axes[0,0].set_ylim(-5,)
axes[0,0].set_xlim(-5,85)
2
3
4
5
6
out:
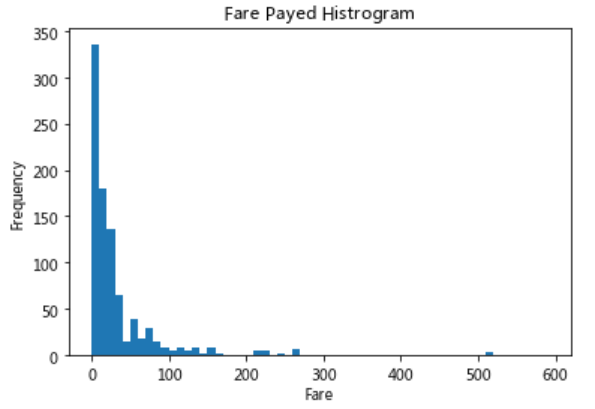
# 绘制一个展示船票价格的直方图
df = titanic.Fare.sort_values(ascending = False)
df
binsVal = np.arange(0,600,10)
binsVal
plt.hist(df, bins = binsVal)
plt.xlabel('Fare')
plt.ylabel('Frequency')
plt.title('Fare Payed Histrogram')
plt.show()
2
3
4
5
6
7
8
9
10
out:
# 本周python学习收获
在做python练习题的过程中,我发现python中连接字符串不能像Java一样简单地只利用“+”来连接,它共有七种方法:
- 来自C语言的%方法:%号格式化字符串的方式继承自古老的C语言,%s是一个占位符,它仅代表一段字符串,并不是拼接的实际内容,实际的拼接内容在一个单独的%后面,放在一个元组里。类似的占位符还有:%d(代表一个整数)、%f(代表一个浮点数)、%x(代表一个浮点数)等。
- format()拼接方式:这种方式使用花括号{}做占位符,在format方法中再转入实际的拼接值。
- ()类似元组方式
- 面向对象模板拼接
- 常用的+方式(!!!有易错点)
- join拼接方式
- f-string方式
关于这其中拼接方式,详情见下 python拼接字符串的七种方法
# 本周学习总结
现在虽然可以看懂基本的程序,但是在面对python练习题时还是会没有思路,不知道从何下手。后续准备在学习基础知识的过程中多多锻炼自己的思维,尽量自己想。解决办法目前就是多看别人的的程序,多自己想,