# 产生原因
为了解决编码器-解码器框架的弊端,提出了 Attention 模型。它与编码器解码器不同的是,它在输出时,会产生一个“注意力范围”表示接下来输出的时候需要重点关注哪些部分,然后根据关注的重点产生下一个输出。
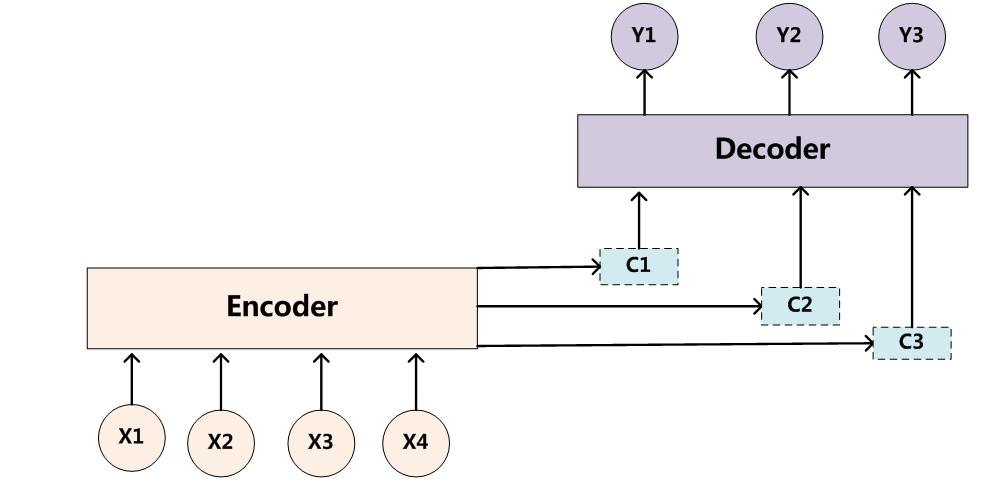
# 概述
注意力模型在模拟人脑。我们在看一幅画时,看似在看整幅画,但其实眼睛重点观察的是其中一部分。也就是说人的注意力在这幅画上并不是平均分配,而是有侧重的。这也是一种资源分配。我们把注意力放在重要的部分,对不重要的部分视而不见。
# 例子
如上面的框架图所示。输入句子 X=(X1,X2,......Xm),中间语义(Context)为 C=F(X1,X2,...Xm),要得到 Y=(Y1,Y2,......Yn)的输出。经过 attention 模型输出的是
其中
- f2 是编码器中的变换函数
- g 是根据单词的中间语义合并成整个句子中间语义的函数
它们的关系是:
Tx 是句子长度,α 是权值,hj=f2(“单词”) 整个过程如下

# 本质思想
计算 Query 与 Key 的相关性,得到 Key 对应的 Value 的权重。对 Value 进行加权求和,得到了 Attention 数值。这个过程可以表示为
- Lx:输入句子的长度
有如下就几个阶段
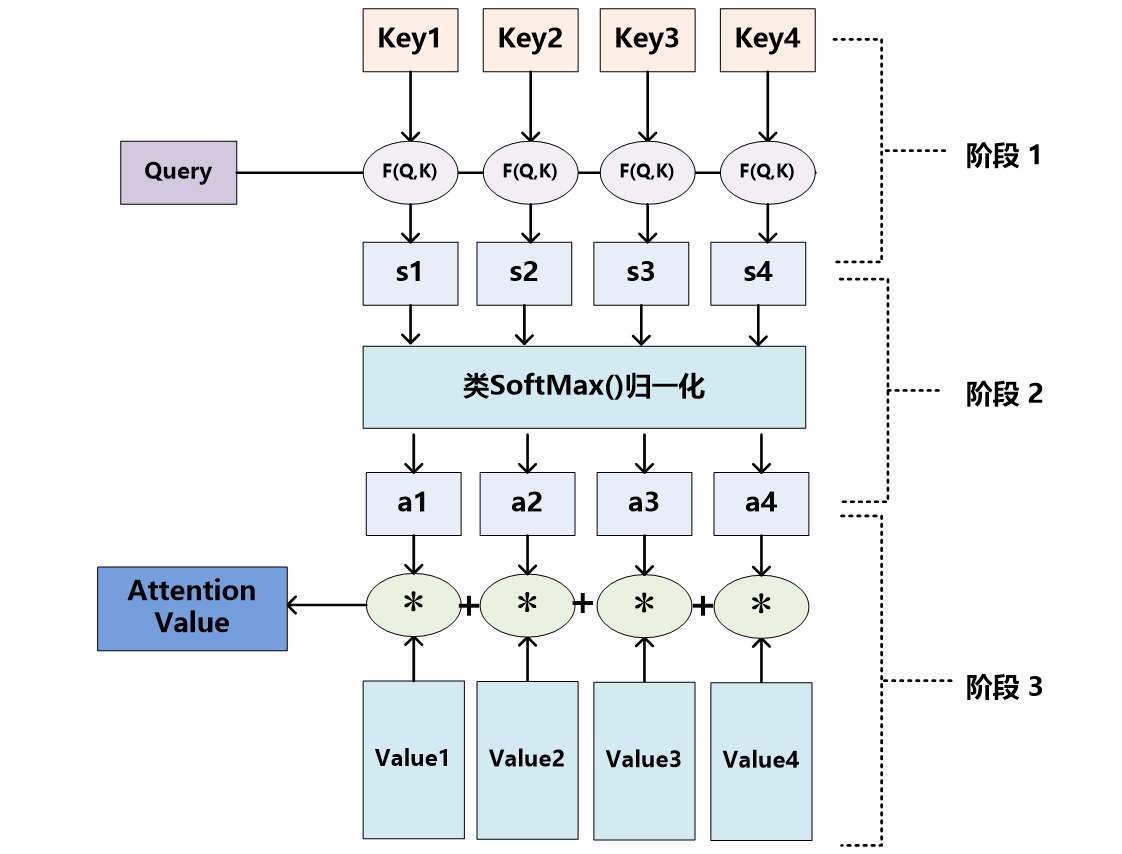
- Query:需要输出的 Target 中的某个元素
:输入的 Source 由一系列 数据对构成 - F(Q,K):是计算 Key 和 Query 相关性的函数
- s:计算 Query 与 Key 相关性后得到的原始数值
- a:s 归一化后的数值
- *:权重 ×value 的结果
- Attention Value:加权求和后得到的 Attention 数值